提供者:孟杨慧
点击访问:MLC语料库
一.语料库简介
- 中国传媒大学有声媒体文本语料库(Media Language Corpus)是一个开放、免费使用的语料库。
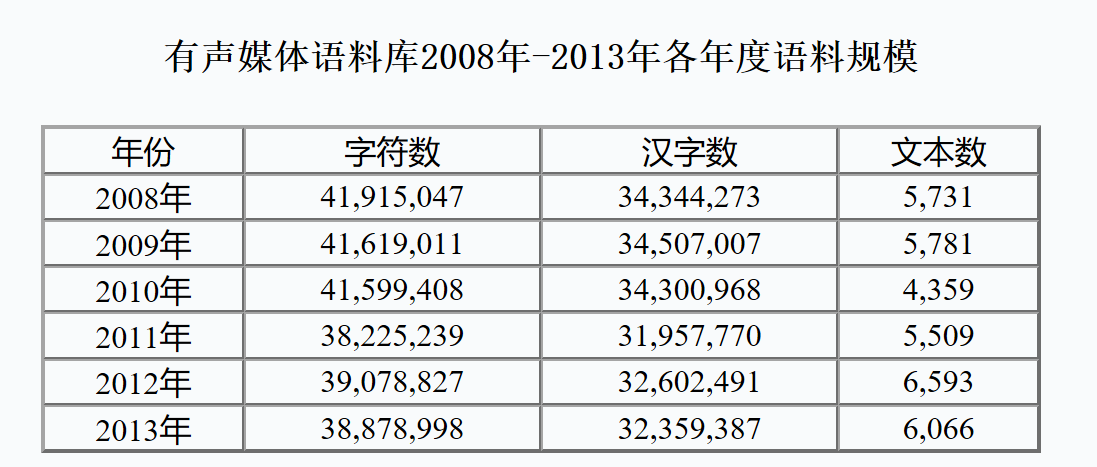
- 语料库包括2008至2013六年的34,039个广播、电视节目的转写文本,总字符数为241,316,530个,总汉字数为200,071,896个。
- 语料库所有语料都进行了元数据标注,检索方便
各年度语料规模如下表:
二.使用教程
1.关键字检索
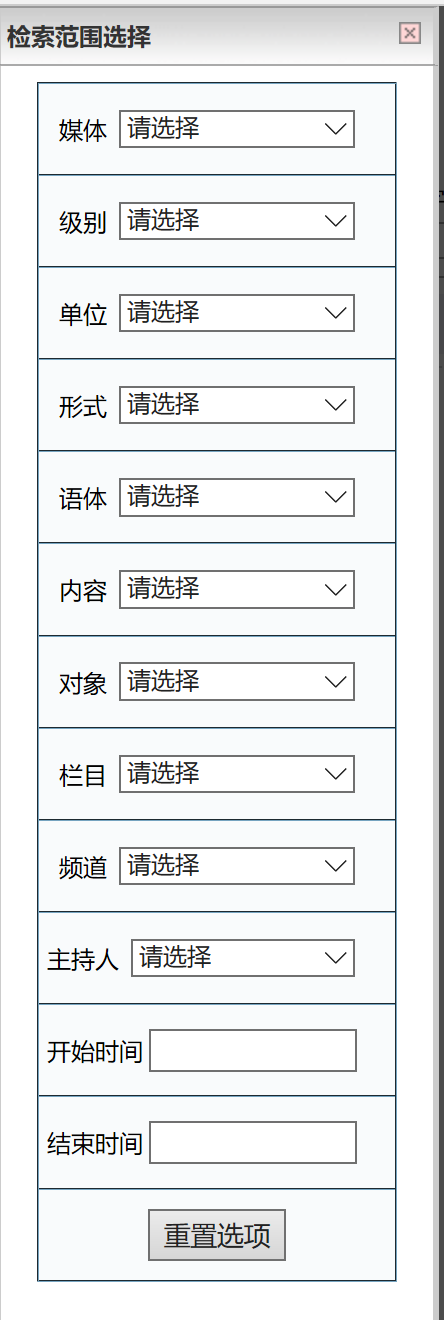
-关键字检索可以在检索页面选定相应的属性项,进行特定时间段(如2008年度、2010至2013年度)、特定媒体(广播、电视)、特定单位(如中央电视台、北京电视台、中央人民广播电台)、特定语言形式(独白、对话)、特定语体(独白形式可分为播报、谈话、解说、朗读;对话形式可分为二人谈、三人谈、多人谈)、特定领域(如新闻、经济、军事)、特定栏目(如《新闻联播》《鲁豫有约》《新闻与报纸摘要》)、特定主持人(如白岩松、陈鲁豫、崔永元)等进行关键字检索。
-各属性之间有级联关系,既可以进行单独属性锁定查询,也可以进行属性间组合查询。如果“媒体”项选定了“广播”,不选择其他,就意味着下面的检索将在所有的广播语料中进行;如果“媒体”项选定了“广播”,那么在栏目项中只能选择广播的节目,不会再出现“新闻联播”这样的电视中的节目名称。如果所有的属性都没有选择,那就意味着将在全部2亿字次的语料中进行检索查询。
2.特定语言格式查询
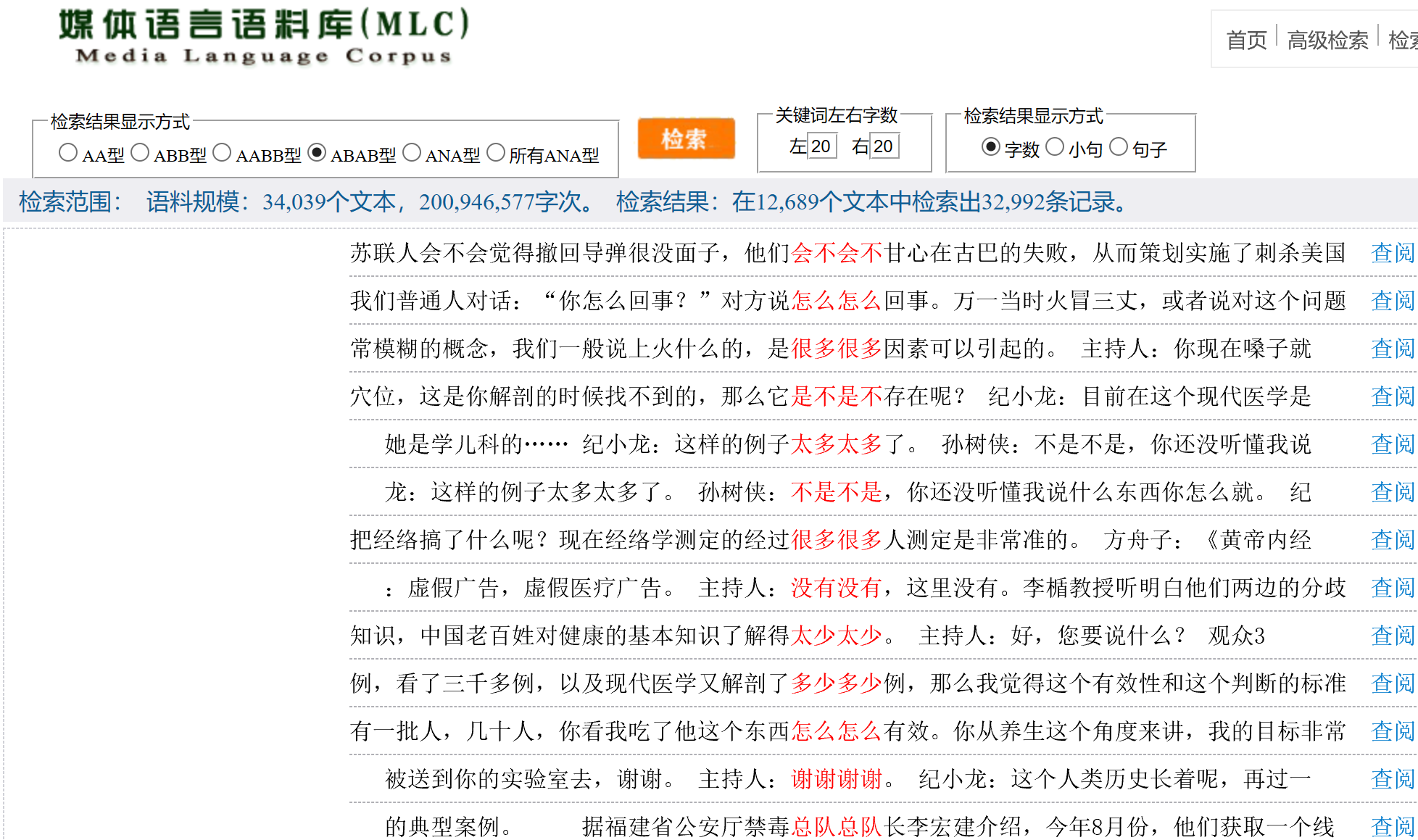
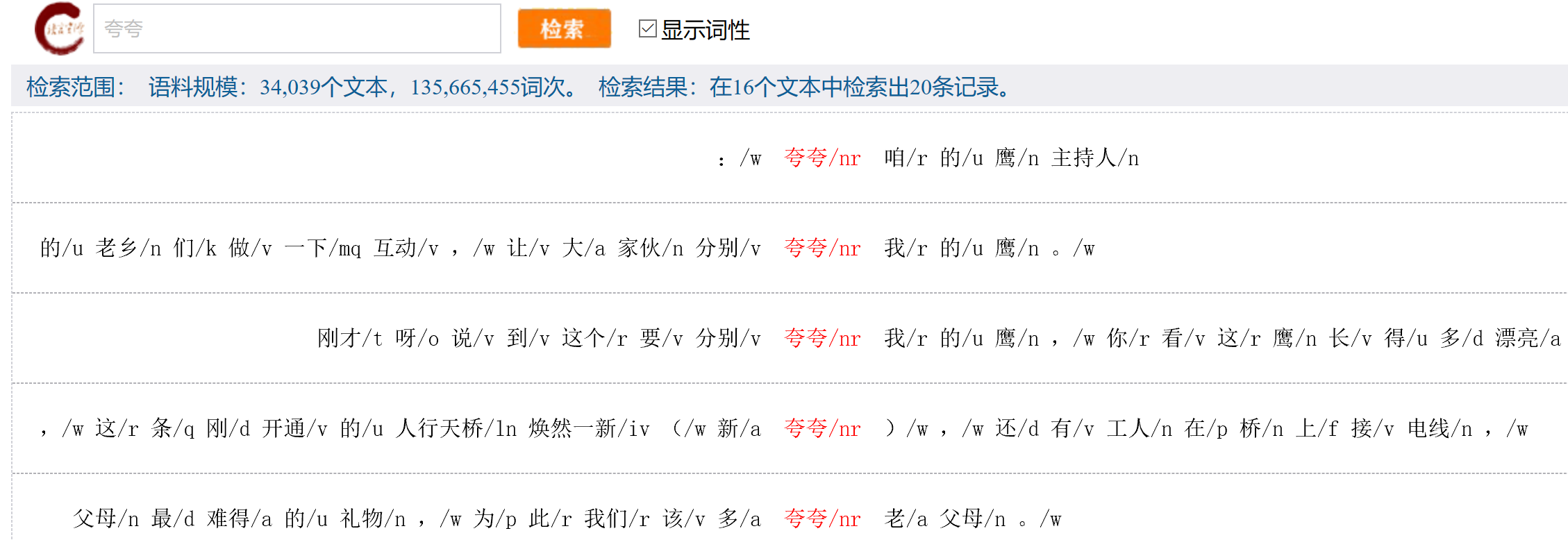
语料库提供了多种查询方式,并且可以进行词性标注,如果查询各种重叠形式,如ABB、AABB、ABAB、A一A、A了A等,可以选择检索页面左边导航中的“检索重叠形式”进行查询。
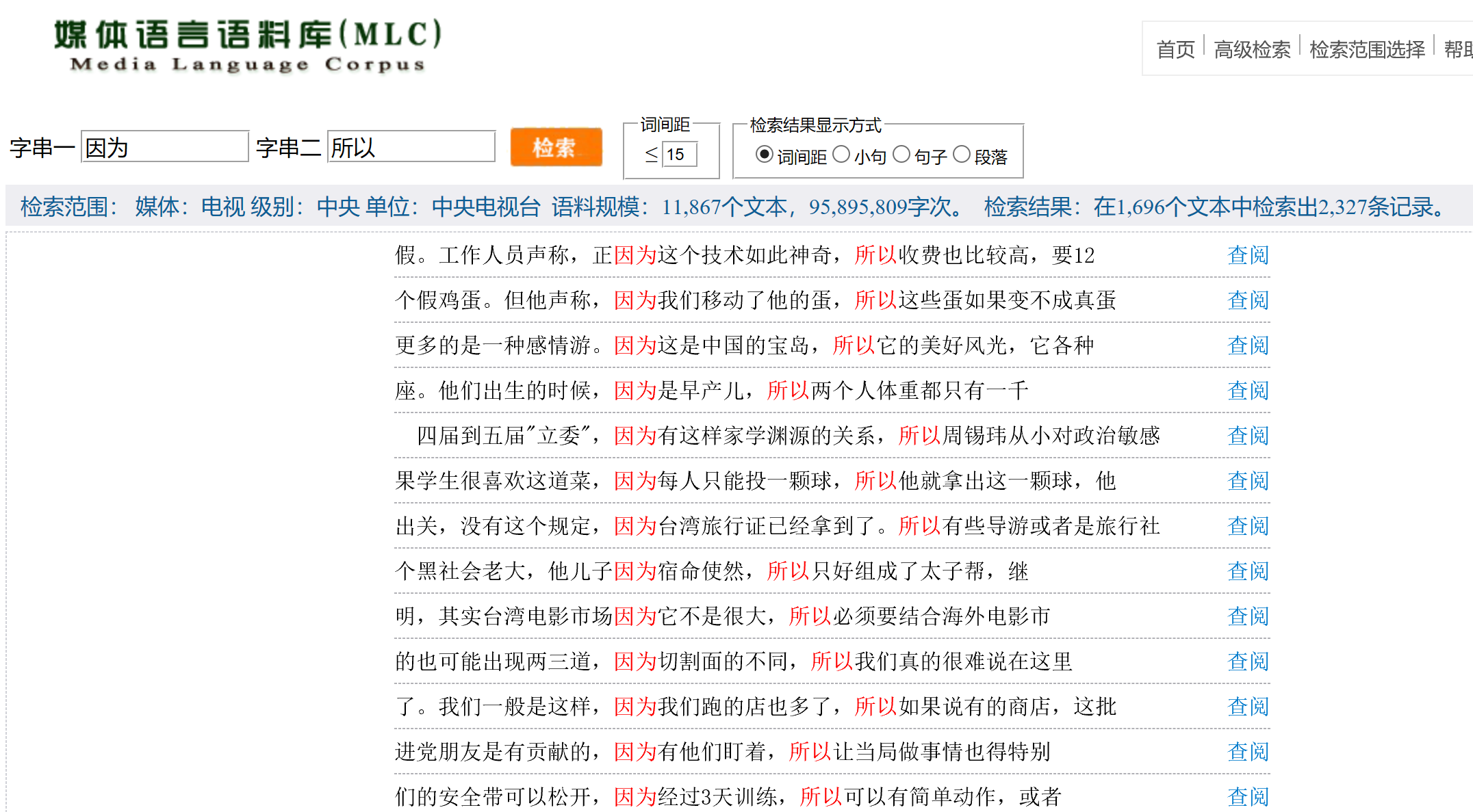
如果需要进行成对词语,如“因为……所以、虽然……但是”等的组合查询,可以选择检索页面左边导航中的“成对字符串检索”
===========================================================================================================
=================================================================================================================
=================================================================================================================
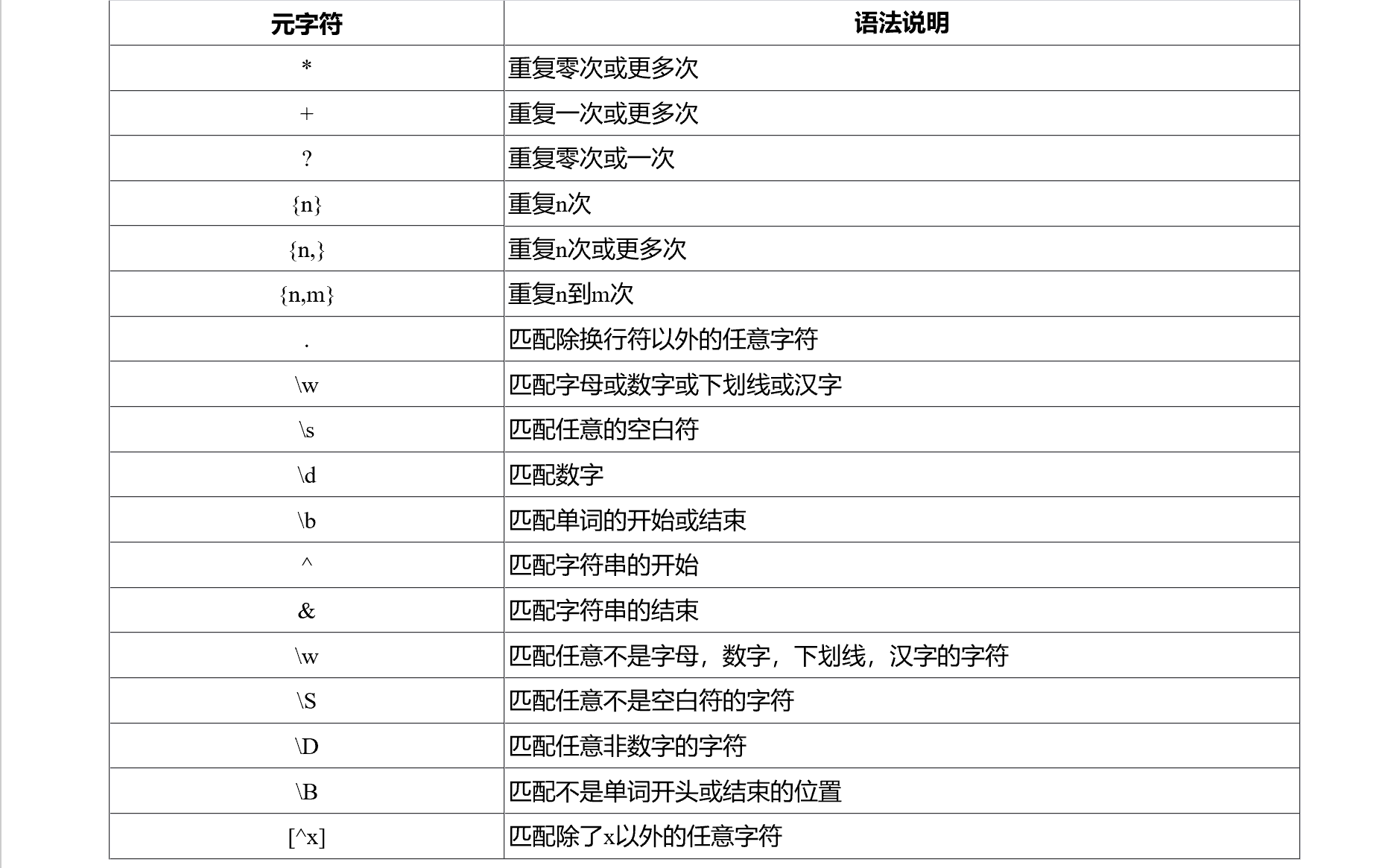
3.正则表达式检索
常用正则表达式符号的说明如下

========================================================================================================================
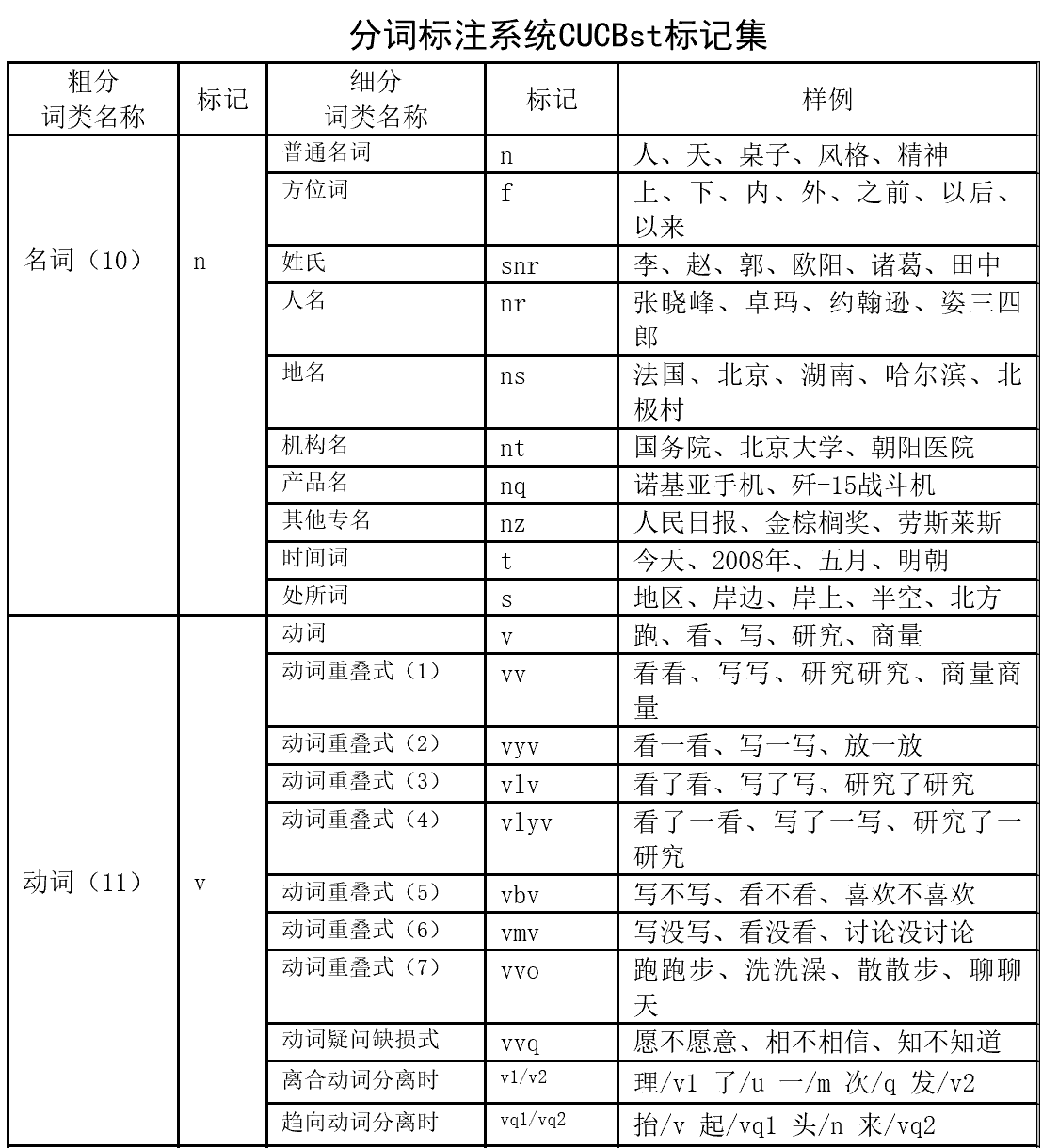
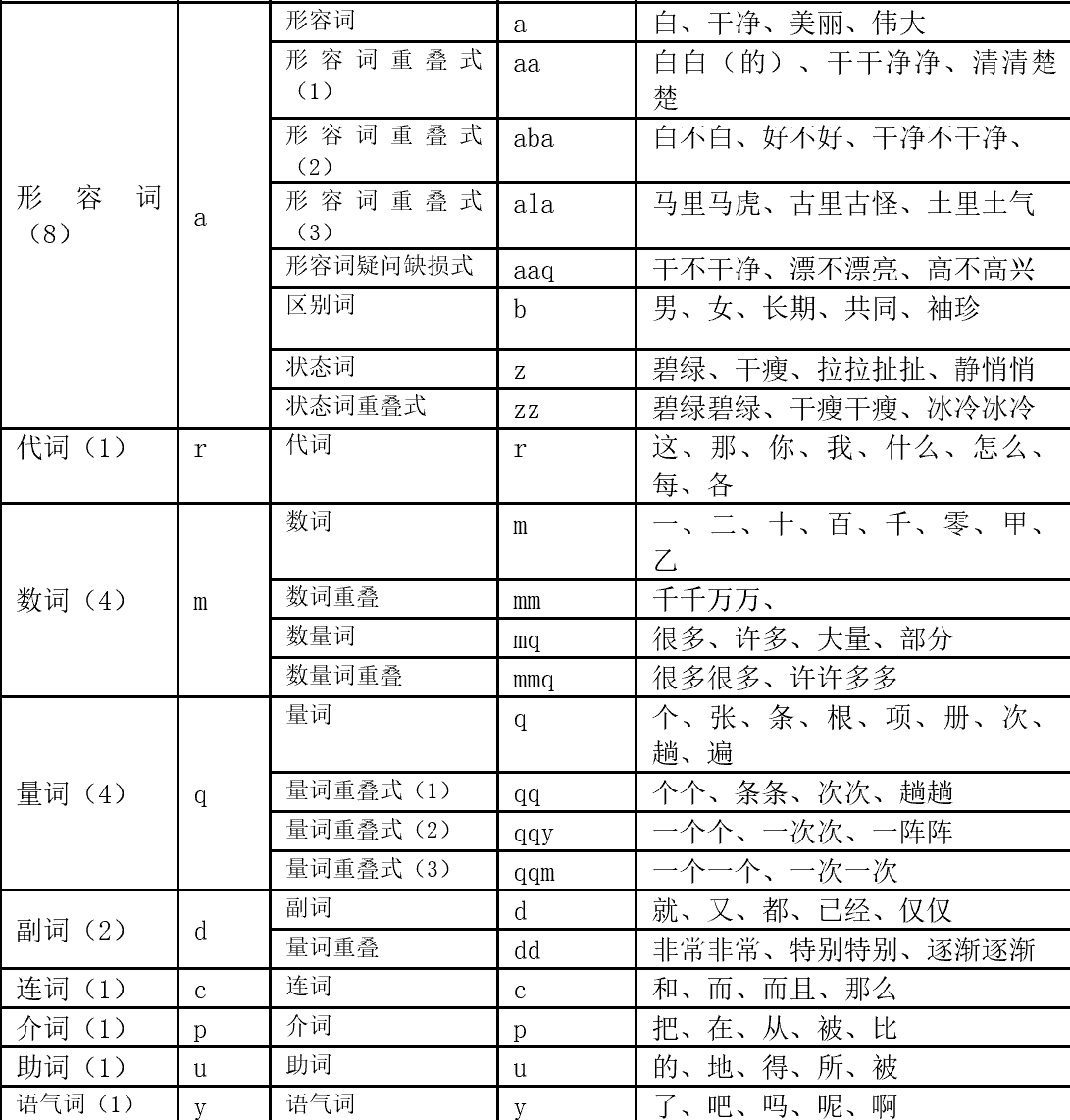
分词标注说明如下:
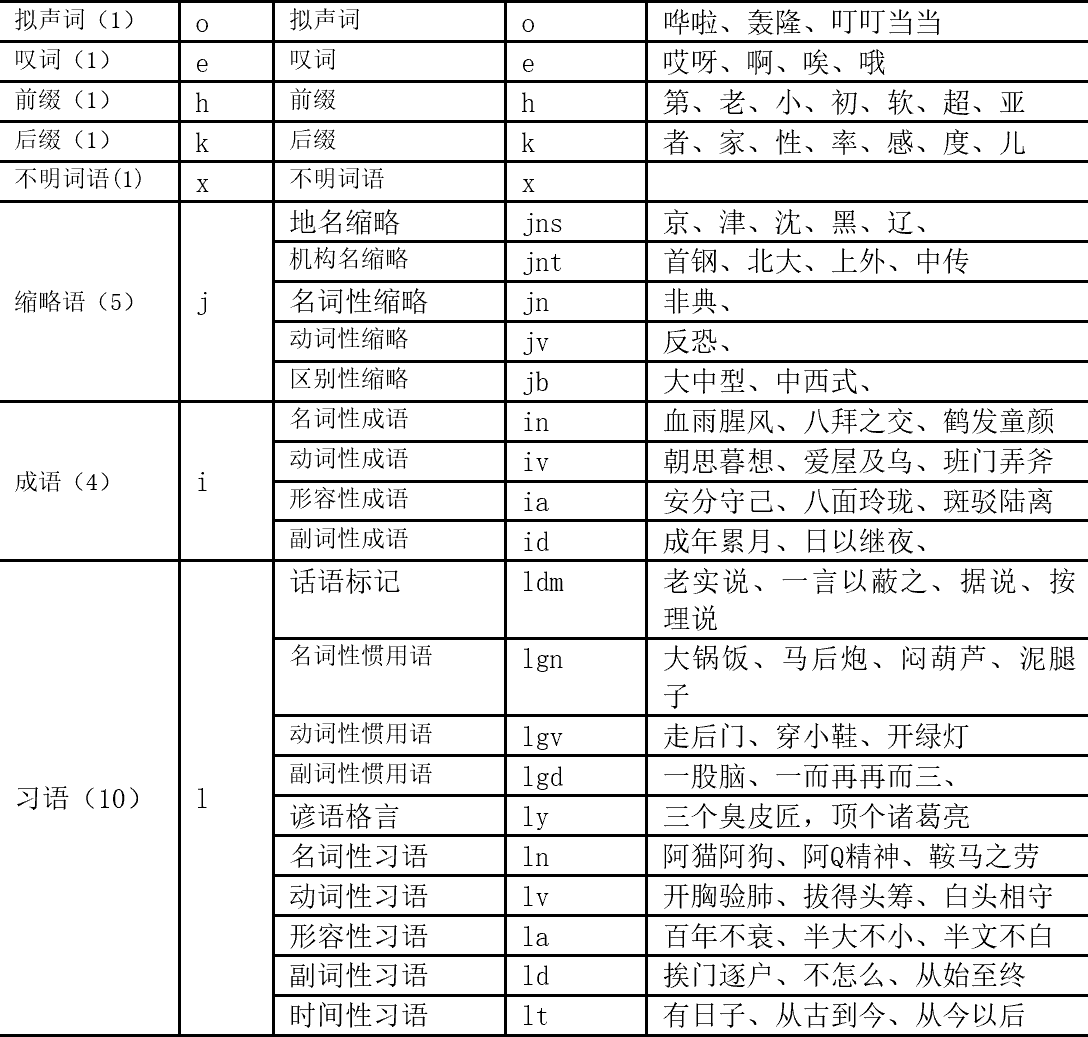
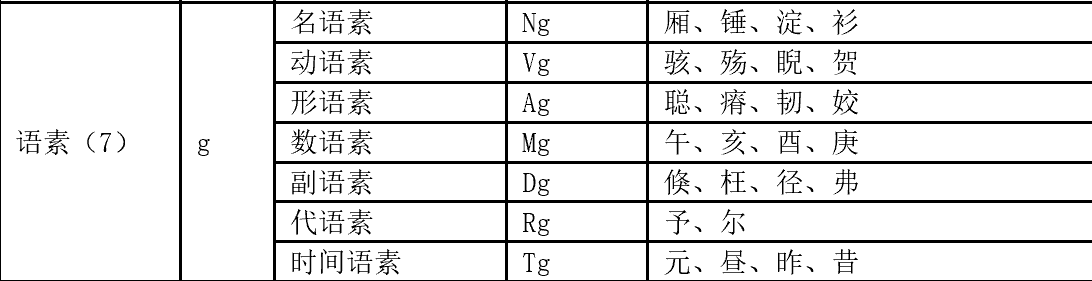
4.二次查询
可以在第一次检索的结果中再设关键字,以得到需要的更精确的检索结果。
5.排序、保存功能
-为帮助研究者更方便地使用本语料库做统计分析,发现语言使用规律,语料库在检索结果页面设计了排序功能,可以根据需要对检索结果进行以关键字为中心的“左排序”或“右排序”。
-为帮助研究者更方便地使用本语料库写作论文选择例句,语料库专门设计了检索结果保存功能,可以把检索结果全部下载保存在本地机的一个文本中,系统没有对下载的数量进行限制。保存前还设计了两个可选择的项目:是否保存出处、是否需要加序号。如果选中“保存出处”,保存结果如下例所示,其中关键字串用“【】”标出。
三. 语料库的局限性
1.查询结果中可能会有一些伪词串,如查询“A了A”,可能会出现“八连组建了建筑工程队”“北京西站加开了开往石家庄”“并集中了中亚地区”等,这些只能由自己甄别。
2.由于语料库较大,如果不设置缩小检索范围,检索时间较长。