提供者:李华勇
简介
海量的数据背景下,人工翻译已经无法承载所有的翻译任务,机器翻译效果并不十分理想,但在有些情况下可以减少理解外语文本所需要的时间和精力。我本人出身英语专业,但是仍然感觉阅读英文文本所花费的时间和精力是中文文本的2-3倍,比如中文一分钟能够阅读600-1000字甚至更多,但英语文章书籍,一般也就200-300单词而已,而且时间长了,大脑更疲劳,难以有效获取信息。所以借助机器翻译,先大致浏览所需理解的外语文本,不失为一种节约时间精力的方式。随着机器翻译的效果越来越好,它的应用场景也越来越广泛,甚至可能彻底改变人类相互沟通的方式。
目前机器翻译已经基本都从传统的统计翻译,变成了神经网络机器翻译,效果有较大的提升,特别是西方语种之间,比如英德互译。而中英互译仍然有差距,不过我想达到令人满意的效果只是时间问题,Google 和 百度 的机器翻译,在某些类型的文档翻译上,已经几乎超过人类,比如科技类的论文,Google 的机器翻译效果尤其好。如果让一个译者去翻译一篇科技类的论文,成本非常高,有很多专业词汇,还有数学符号,懂的人并不多,翻译起来也费时费力,但机器翻译却对这类文本有着很高的效率,十分令人欣喜。
OpenNMT 是一个由 Harvard NLP (哈佛大学自然语言处理研究组) 开源的 Torch 神经网络机器翻译系统。
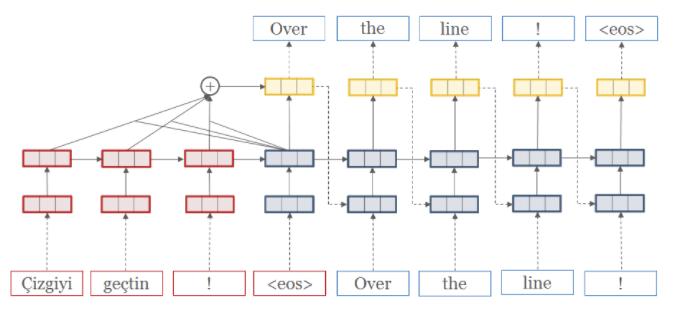
特点
简单的通用接口,只需要源/目标文件。
快速高性能GPU训练和内存优化。
提高翻译性能的最新的研究成果。
可配对多种语言的预训练模型(即将推出)。
允许其他序列生成任务的拓展,如汇总和图文生成
快速开始
OpenNMT 包含三个命令
1) 数据预处理
th preprocess.lua -train_src data/src-train.txt -train_tgt data/tgt-train.txt -valid_src data/src-val.txt -valid_tgt data/tgt-val.txt -save_data data/demo
2) 模型训练
th train.lua -data data/demo-train.t7 -save_model model
3) 语句翻译
th translate.lua -model model_final.t7 -src data/src-test.txt -output pred.txt
相关资料
- Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
- Wu Y, Schuster M, Chen Z, et al. Google’s neural machine translation system: Bridging the gap between human and machine translation[J]. arXiv preprint arXiv:1609.08144, 2016.