提供者:刘晓
地址:https://blog.csdn.net/amusi1994/article/details/75331115
简介
MNIST(维基百科)是一个最大的手写字符数据集,其经常被应用在机器学习领域,用于训练和测试。
MNIST对于机器学习,就好比于Hello world相比于编程学习。
MNIST是一个简单的计算机视觉数据库,其包含了很多张手写数字图像,如: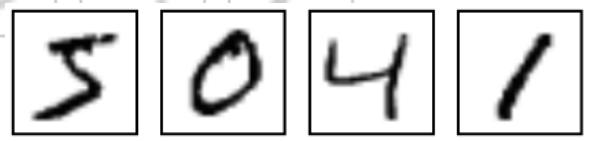
来自NIST的原始黑白(双色)图像尺寸标准化,以适应20×20像素Box,同时保持其长宽比。由于归一化算法使用的抗混叠技术,所得图像包含灰度级。通过计算像素的质心并转换图像以使该点位于28x28场的中心,图像以28×28图像为中心。
通过一些分类方法(特别是基于模板的方法,例如SVM和K-最近邻),当数字以边界框为中心而不是质心时,错误率提高。
MNIST数据库由NIST的特殊数据库3和特殊数据库1构成,其中包含手写数字的二进制图像。 NIST原来指定为SD-3作为训练集,SD-1作为其测试集。然而,SD-3比SD-1更cleaner和更容易识别。其原因是在普查局员工(Census Bureau employees)中收集SD-3,在高中生(high-school students)中收集SD-1。从学习实验中得出明确的结论要求,结果与完整的样本集中的训练集和测试的选择无关。因此,有必要通过混合NIST的数据集来构建一个新的数据库。
MNIST训练集由SD-3的30,000个模式和来自SD-1的30,000个模式组成。我们的测试套件由SD-3的5,000个模式和来自SD-1的5,000个模式组成。 60,000个模式训练集包含大约250位作家的例子。我们确保训练集和测试集的作者集合是不相交的。
SD-1包含由500个不同作者撰写的58,527位数字图像。与SD-3相反,其中来自每个写入器的数据块按顺序出现,SD-1中的数据被加扰。 SD-1的作者身份可用,我们使用这些信息来解读作者。然后我们将SD-1分成两部分:由前250位作家撰写的角色进入我们的新的训练集。剩下的250位作家被放在我们的测试集中。因此,我们有两套,每套有近30,000个例子。新的训练集完成了SD-3的例子,从模式#0开始,全面训练了6万个训练模式。类似地,新的测试集完成了SD-3示例,从模式#35,000开始,以全面设置6万个测试模式。只有10,000个测试图像的子集(来自SD-1的5,000个和来自SD-3的5,000个)在本网站上可用。完整的6万个样本训练集可用。
已经通过该训练集和测试集测试了许多方法。这里有几个例子。有关方法的详细信息将在即将发布的论文中给出。其中一些实验使用数据库版本,其中将去偏移的输入图像(通过计算最靠近垂直线的形状的主轴,并移动线条使其垂直)。在其他一些实验中,训练集增加了原始训练样本的人为扭曲版本。失真是移位,缩放,偏移和压缩的随机组合。
在这篇文章中,通过读取MNIST数据集(图像和标签数据),显示图像。
主要内容与使用教程
手写数字的MNIST数据库可从官网获得,其中包含60,000个示例的训练集以及10,000个示例的测试集。它是NIST提供的更大集合的子集。这些数字已经过尺寸标准化并以固定尺寸的图像为中心。 对于那些想要在实际数据上尝试学习技术和模式识别方法,同时在预处理和格式化上花费最少的人,这是一个很好的数据库。
下载MNIST数据集
官网下载四个文件,分别是t10k-images-idx3-ubyte(训练集–图像) 、t10k-labels-idx1-ubyte(训练集–标签)、t10k-images-idx3-ubyte(测试集–图像)、t10k-labels.idx1-ubyte(测试集–标签):
MNIST结构分析
mnist的结构如下,选取train-images
TRAINING SET IMAGE FILE (train-images-idx3-ubyte):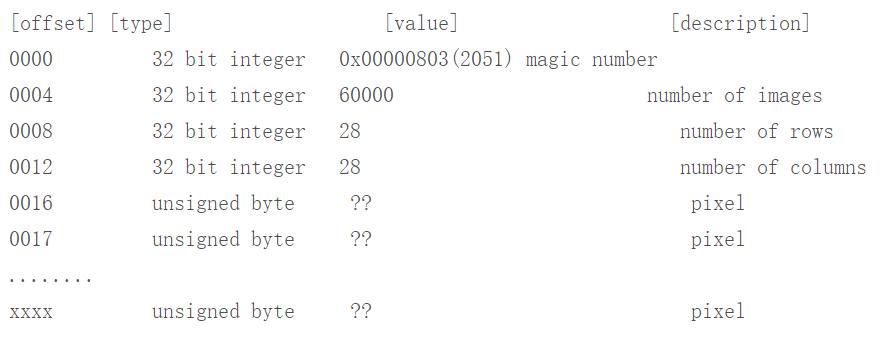
读取图像数据
先使用二进制方式读取文件
filename = '路径名/train-images.idx3-ubyte'
binfile = open(filename , 'rb') # python3 'r' but python2 'rd'
buf = binfile.read()
使用struct解包
index = 0
magic, numImages, numRows, numColumns = struct.unpack_from('>IIII' , buf , index)
index += struct.calcsize('>IIII')
‘>IIII’是指使用大端法读取4个unsigned int32
读取图像测试
im = struct.unpack_from('>784B' , buf , index)
index += struct.calcsize('>784B')
im = np.array(im)
im = im.reshape(28,28)
fig = plt.figure()
plotwindow = fig.add_subplot(111)
plt.imshow(im , cmap = 'gray')
plt.show()
(28,28)是MNIST图像的固定格式;
‘>7894B’是指用大端法读取784个unsigned byte字节,因为28*28 = 784
读取标签数据
每次读入2个unsigned int的元数据,并且相应的调整位置,代码如下:
<span style="font-size:14px;">magic, self.train_label_num = struct.unpack_from('>II', buf, index)
index += struct.calcsize('>II')
for i in range(self.train_label_num):
# for x in xrange(2000):
label_item = int(struct.unpack_from('>B', buf, index)[0])
self.train_label_list[ i , : ] = label_item
index += struct.calcsize('>B')</span>
代码:
import numpy as np
import struct
import matplotlib.pyplot as plt
filename = 'F:/Pro_Data/Deep&Machine Learning/Deep Learning/MNIST/Data Sets/train-images.idx3-ubyte'
binfile = open(filename , 'rb') # python3 'r' but python2 'rd'
buf = binfile.read()
index = 0
magic, numImages, numRows, numColumns = struct.unpack_from('>IIII' , buf , index)
index += struct.calcsize('>IIII')
im = struct.unpack_from('>784B' , buf , index)
index += struct.calcsize('>784B')
im = np.array(im)
im = im.reshape(28,28)
fig = plt.figure()
plotwindow = fig.add_subplot(111)
plt.imshow(im , cmap = 'gray')
plt.show()
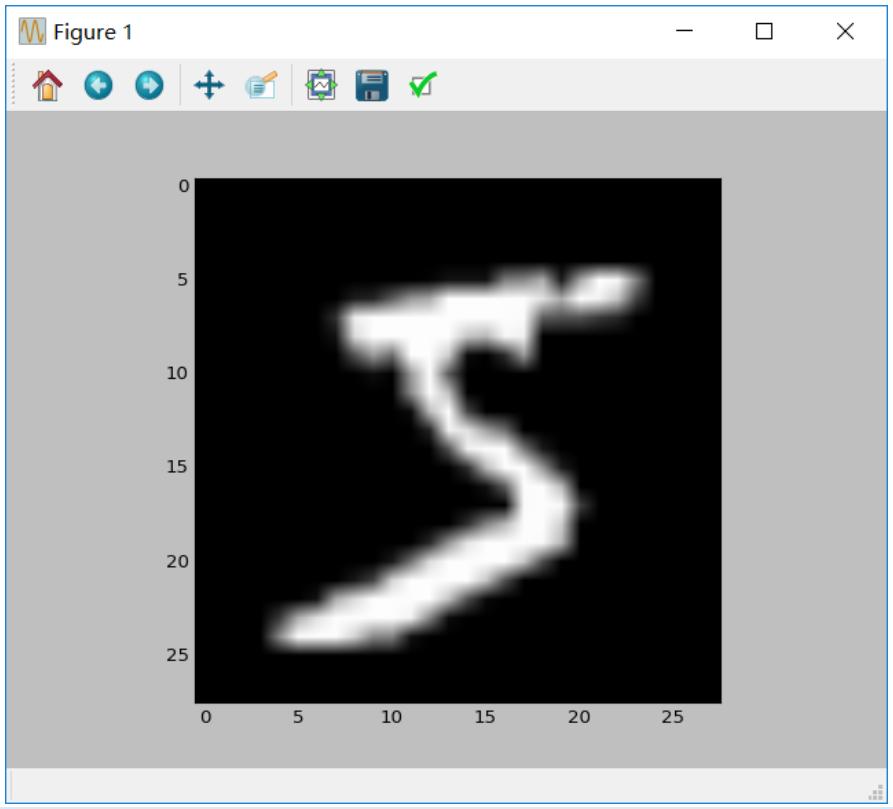
输出结果:
相关资源
官网: http://yann.lecun.com/exdb/mnist/
维基百科: https://en.wikipedia.org/wiki/MNIST_database
ConvNetJS MNIST demo: https://cs.stanford.edu/people/karpathy/convnetjs/demo/mnist.html
Tensorflow: https://www.tensorflow.org/get_started/mnist/beginners