简介
数据集概述
该数据集从在线百科全书维基百科的271篇文章中抽取了1127段,并标记了总共4701个关系实例。 除了大量的人际关系之外,还包括人与组织之间的联系,以及诸如生日和jobTitle等传记事实。 总的来说,训练数据中有53个标签。
示例: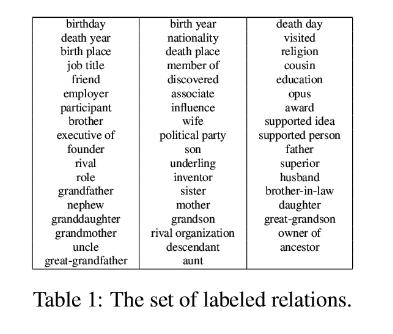
相关论文
1.Culotta A, Mccallum A, Betz J. Integrating probabilistic extraction models and data mining to discover relations and patterns in text[C]// Main Conference on Human Language Technology Conference of the North American Chapter of the Association of Computational Linguistics. Association for Computational Linguistics, 2006:296-303.
2.Dmitry Zelenko, Chinatsu Aone, and Anthony Richardella.2003. Kernel methods for relation extraction. Journal of Machine Learning Research, 3:1083–1106.
3.Sunita Sarawagi and William W. Cohen. 2004. Semi-markov conditional random fields for information extraction. In NIPS 04.