提供者:卢梦依
下载地址:https://github.com/FerreroJeremy/Cross-Language-Dataset
简介
数据集概述
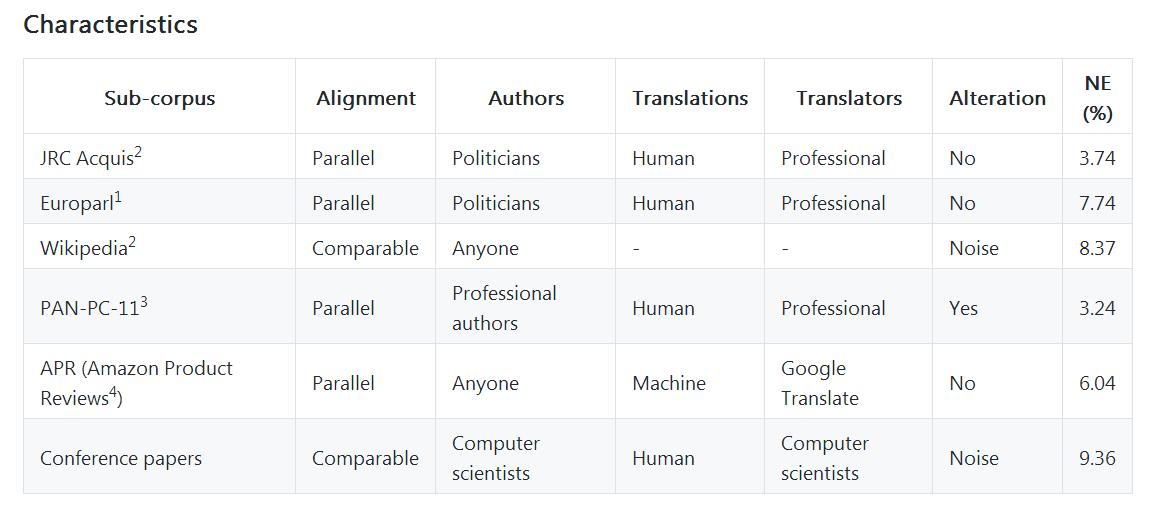
该数据集是用于跨语言文本相似性检测的多语言,多风格和多粒度数据集。这个数据集的特征如下:
- 包含三种语言:法语,英语和西班牙语;
- 提出了不同粒度的跨语言对齐信息:文档级,句级和块级;
- 基于平行和可比较的语料库;
- 包含人和机器翻译的文本;
- 其中的一部分已经被修改(为了使跨语言相似性检测更复杂),而其余部分没有噪音;
- 文件由多种类型的作者撰写:从一般人士到专业人士。
文件
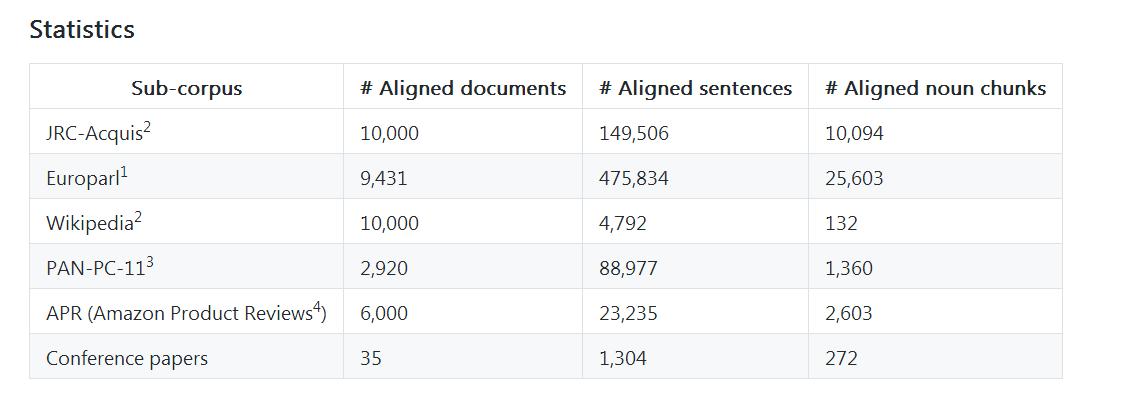
本数据集部分详细统计如下:
相关论文
1.A Multilingual, Multi-Style and Multi-Granularity Dataset for Cross-Language Textual Similarity Detection. Jérémy Ferrero, Frédéric Agnès, Laurent Besacier and Didier Schwab. In the 10th edition of the Language Resources and Evaluation Conference (LREC 2016).
2.Philipp Koehn (2005). Europarl: A Parallel Corpus for Statistical Machine Translation. In Conference Proceedings: the tenth Machine Translation Summit, pages 79–86. AAMT.
3.Martin Potthast, Alberto Barrón-Cedeño, Benno Stein, and Paolo Rosso (2011). Cross-Language Plagiarism Detection.In Language Ressources and Evaluation, volume 45, pages 45–62.
4.Martin Potthast, Benno Stein, Alberto Barrón-Cedeño, and Paolo Rosso (2010). An Evaluation Framework for Plagiarism Detection. In Proceedings of the 23rd International Conference on Computational Linguistics (COLING 2010), Beijing, China, August 2010. Association for Computational Linguistics.