提供者:卢梦依
下载地址:http://data.dws.informatik.uni-mannheim.de/rmlod/LOD_ML_Datasets/
简介
数据集概述
近年来,已经提出了几种在语义网上进行机器学习的方法。 但是,这些方法之间没有广泛的比较,特别是由于缺乏公开可用的公认基准数据集。 在这里,我们提供了来自现有语义Web数据集以及与链接开放数据云中的数据集相关的外部分类和回归问题的不同大小的22个基准数据集的集合。 这样的数据集合可以用来进行定量性能测试和方法的系统比较,由于数据集的数量,这也可以确定研究结果的统计显着性。
我们的数据集合包括22个数据集,分为三类:
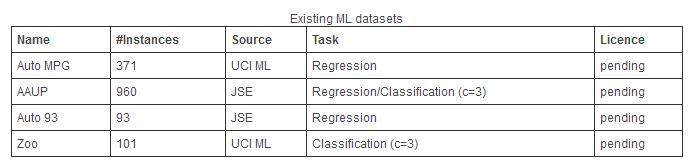
- 机器学习实验中常用的现有数据集
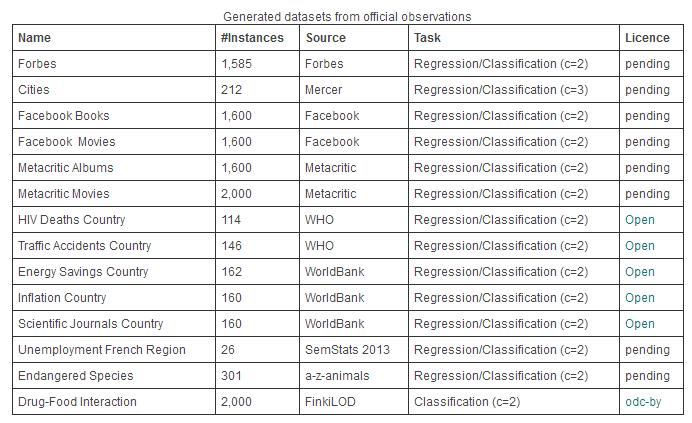
- 由官方观察产生的数据集
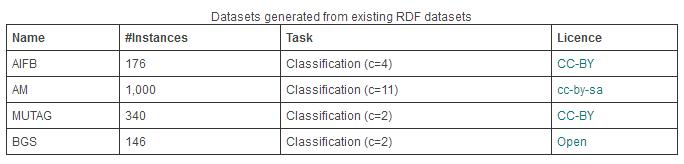
- 数据集从现有的RDF数据集生成。
前两个类别中的每个数据集最初都链接到DBpedia。 这主要有两个原因:(1)DBpedia是跨域知识库,可用于来自非常不同的主题域的数据集;(2)DBpedia Lookup和DBpedia Spotlight等工具可以轻松地将外部数据集链接到DBpedia。 然而,DBpedia可以被看作是关联数据网站的入口点,许多数据集链接到和来自DBpedia。 实际上,我们使用最初的DBpedia链接为每个实体检索YAGO和Wikidata的外部链接。 这些链接可用于系统评估不同LOD数据集的数据在不同学习任务中的相关性。
文件
本数据集部分详细统计如下:
相关论文
1.Ristoski, P., de Vries, G.K.D., Paulheim, H.: A collection of benchmark datasets for systematic evaluations of machine learning on the semantic web. In: International Semantic Web Conference (To Appear). Springer (2016)