提供者:李华勇
地址:http://www.cs.upc.edu/~srlconll/
背景介绍
自然语言分析技术大致分为三个层面:词法分析、句法分析和语义分析。语义角色标注是实现浅层语义分析的一种方式。在一个句子中,谓词是对主语的陈述或说明,指出“做什么”、“是什么”或“怎么样,代表了一个事件的核心,跟谓词搭配的名词称为论元。语义角色是指论元在动词所指事件中担任的角色。主要有:施事者(Agent)、受事者(Patient)、客体(Theme)、经验者(Experiencer)、受益者(Beneficiary)、工具(Instrument)、处所(Location)、目标(Goal)和来源(Source)等。
请看下面的例子,“遇到” 是谓词(Predicate,通常简写为“Pred”),“小明”是施事者(Agent),“小红”是受事者(Patient),“昨天” 是事件发生的时间(Time),“公园”是事情发生的地点(Location)。
1 | [小明]Agent[昨天]Time[晚上]Time在[公园]Location[遇到]Predicate了[小红]Patient。 |
语义角色标注(Semantic Role Labeling,SRL)以句子的谓词为中心,不对句子所包含的语义信息进行深入分析,只分析句子中各成分与谓词之间的关系,即句子的谓词(Predicate)- 论元(Argument)结构,并用语义角色来描述这些结构关系,是许多自然语言理解任务(如信息抽取,篇章分析,深度问答等)的一个重要中间步骤。在研究中一般都假定谓词是给定的,所要做的就是找出给定谓词的各个论元和它们的语义角色。
数据集介绍
我们选用CoNLL 2005SRL任务开放出的数据集作为示例。需要特别说明的是,CoNLL 2005 SRL任务的训练数集和开发集在比赛之后并非免费进行公开,目前,能够获取到的只有测试集,包括Wall Street Journal的23节和Brown语料集中的3节。
原始数据中同时包括了词性标注、命名实体识别、语法解析树等多种信息。
原始数据需要进行数据预处理才能被使用,预处理包括下面几个步骤:
- 将文本序列和标记序列其合并到一条记录中;
- 一个句子如果含有n个谓词,这个句子会被处理n次,变成n条独立的训练样本,每个样本一个不同的谓词;
- 抽取谓词上下文和构造谓词上下文区域标记;
- 构造以BIO法表示的标记;
- 依据词典获取词对应的整数索引。
预处理完成之后一条训练样本包含9个特征,分别是:句子序列、谓词、谓词上下文(占 5 列)、谓词上下区域标志、标注序列。下表是一条训练样本的示例。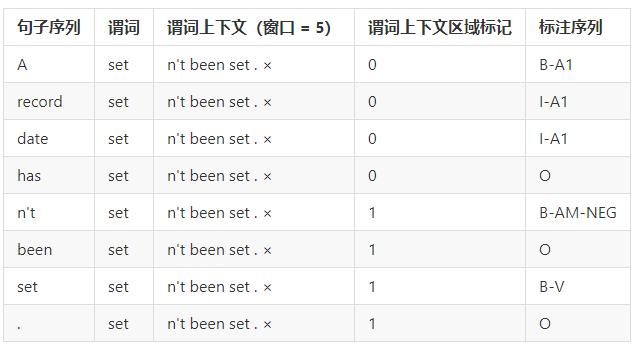
下载地址
http://www.cs.upc.edu/~srlconll/soft.html
相关论文
- Carreras X, Màrquez L. Introduction to the CoNLL-2005 shared task: Semantic role labeling[C]//Proceedings of the ninth conference on computational natural language learning. Association for Computational Linguistics, 2005: 152-164.
- Palmer M, Gildea D, Xue N. Semantic role labeling[J]. Synthesis Lectures on Human Language Technologies, 2010, 3(1): 1-103.