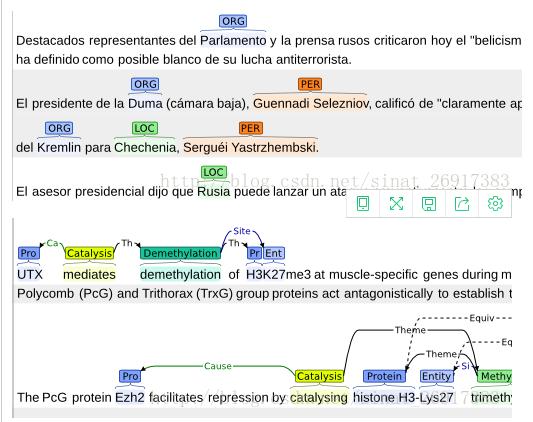
提供者:刘晓
地址:http://kdd.ics.uci.edu/databases/CorelFeatures/CorelFeatures.html
简介
该数据集包含从Corel图像集合中提取的图像特征。基于颜色直方图,颜色直方图布局,颜色矩和共生纹理,提供了四组特征。
数据集描述
数据特征
原始图像集合是从Corel的http://corel.digitalriver.com/获得的。有来自各个类别的68,040张照片图像。以下是图片的示例(jpg缩略图):





从每幅图像中提取四组特征:
- 颜色直方图
- 颜色直方图布局
- 色彩时刻
- 共现纹理
颜色直方图:32维(8 x 4 = H x S)
- HSV色彩空间分为32个子空间(32种颜色:8个H范围和4个S范围)。
- 图像的ColorHistogram中每个维度的值是整个图像中每种颜色的密度。
- 直方图交叉点(两个图像的ColorHistogram之间的重叠区域)可用于测量两个图像之间的相似度。
颜色直方图布局:32维(4 x 2 x 4 = H x S x子图像)
- 每个图像被分成4个子图像(一个水平分割和一个垂直分割)。
- 计算每个子图像的4x2颜色直方图。
- 直方图交集可用于测量两幅图像之间的相似度。
色彩时刻:9个尺寸(3 x 3)
- 这9个值是:
- (HSV颜色空间中的H,S和V各一个) 意思,
- 标准差
- 偏度。
- 两幅图像的色彩矩之间的欧几里得距离可以用来表示两幅图像之间的不相似性(距离)。
共生纹理:16维(4 x 4)
- 图像被转换成16个灰度图像。
计算4个方向上的共同出现(水平,垂直和两个对角线方向)。这16个值是:(每个方向一个)
- 第二个角度
- 对比
- 差矩
- 熵
两幅图像的ColorMoments之间的欧几里得距离可用于测量两幅图像之间的不相似性(距离)。
数据格式
每组功能都存储在一个单独的文件中。对于每个文件,一条线对应于一个图像。一行中的第一个值是图像ID,随后的值是图像的特征向量(例如颜色直方图等)。所有文件中相同的图像具有相同的ID,但图像ID与图像文件名不同。
数据集下载
- ColorHistogram.asc.gz (4.9M; 20.0M uncompressed)
- LayoutHistogram.asc.gz (5.0M; 20.0M uncompressed)
- ColorMoments.asc.gz (2.6M; 6.2M uncompressed)
- CoocTexture.asc.gz (4.6M; 10.8M uncompressed)
相关论文
[1] Michael Ortega, Yong Rui, Kaushik Chakrabarti, Kriengkrai Porkaew, Sharad Mehrotra, and Thomas S. Huang, Supporting Ranked Boolean Similarity Queries in MARS, IEEE Transaction on Knowledge and Data Engineering, Vol. 10, No. 6, Pages 905-925, December 1998.
[2] Kaushik Chakrabarti, and Sharad Mehrotra, The Hybrid Tree: An Index Structure for High Dimensional Feature Spaces, 1999 IEEE International Conference on Data Engineering (ICDE), Pages 440-447, February, 1999.
[3] Kriengkrai Porkaew, Kaushik Chakrabarti, and Sharad Mehrotra, Query Refinement for Multimedia Retrieval and its Evaluation Techniques in MARS, 1999 ACM International Multimedia Conference, Orlando, Florida, Oct 30 - Nov 4, 1999.
[4] Kaushik Chakrabarti, Kriengkrai Porkaew, and Sharad Mehrotra, Efficient Query Refinement in Multimedia Databases, Submitted for publication,